Resume Parsing Explained: A Job Seeker's 2026 Guide

Resume parsing is defined as the automated process by which software extracts structured data from a resume and feeds it directly into an applicant tracking system (ATS). Every time you submit a job application online, a parser reads your resume before any human does. Understanding what is resume parsing gives you a real advantage. The technology decides whether your qualifications reach a recruiter’s screen or disappear into a digital void. This guide explains how parsing works, why it matters, and exactly what you can do to make sure your resume survives the process.
What is resume parsing and how does it work?
Resume parsing is the technical backbone of modern recruitment. The standard parsing pipeline runs through five distinct stages: text extraction, tokenization, section classification, named entity recognition, and structured output in JSON format. Each stage builds on the last, and a failure at any point can mean your data never reaches the recruiter.
Here is what each stage actually does:
- Text extraction. The parser pulls raw text from your file. Text-based PDFs and .docx files work well. Scanned images and JPGs do not.
- Tokenization. The extracted text is broken into individual words and phrases. This is where the system starts to “read.”
- Section classification. The parser identifies which block of text belongs to which resume section, such as Work Experience, Education, or Skills.
- Named entity recognition (NER). AI identifies specific data points: job titles, company names, dates, degrees, and certifications.
- Structured output. All extracted data is organized into a clean, searchable format and pushed into the ATS database.
Natural language processing (NLP) powers the section classification and NER stages. NLP allows the parser to understand context, not just keywords. That means it can recognize “Software Engineer” and “Sr. SWE” as related terms rather than treating them as completely different strings.
Pro Tip: Open your resume PDF and try to highlight the text. If you cannot highlight individual words, the file is a scanned image. A parser cannot read it, and your application will likely fail before a human ever sees it.

Modern parsers blend rule-based logic with machine learning. Rule-based systems follow fixed patterns, while machine learning models adapt to variations in formatting and language. Together, they handle a wide range of resume styles. However, they are still sensitive to unusual layouts, graphics-heavy designs, and non-standard section headers.
What are the main benefits of resume parsing?
Resume parsing technology delivers measurable gains for both recruiters and job seekers. Recruiters using AI-based parsing have reduced time-to-hire by 30% and can process a single resume in under 10 seconds. That speed means your application enters the recruiter’s pipeline almost instantly after submission.
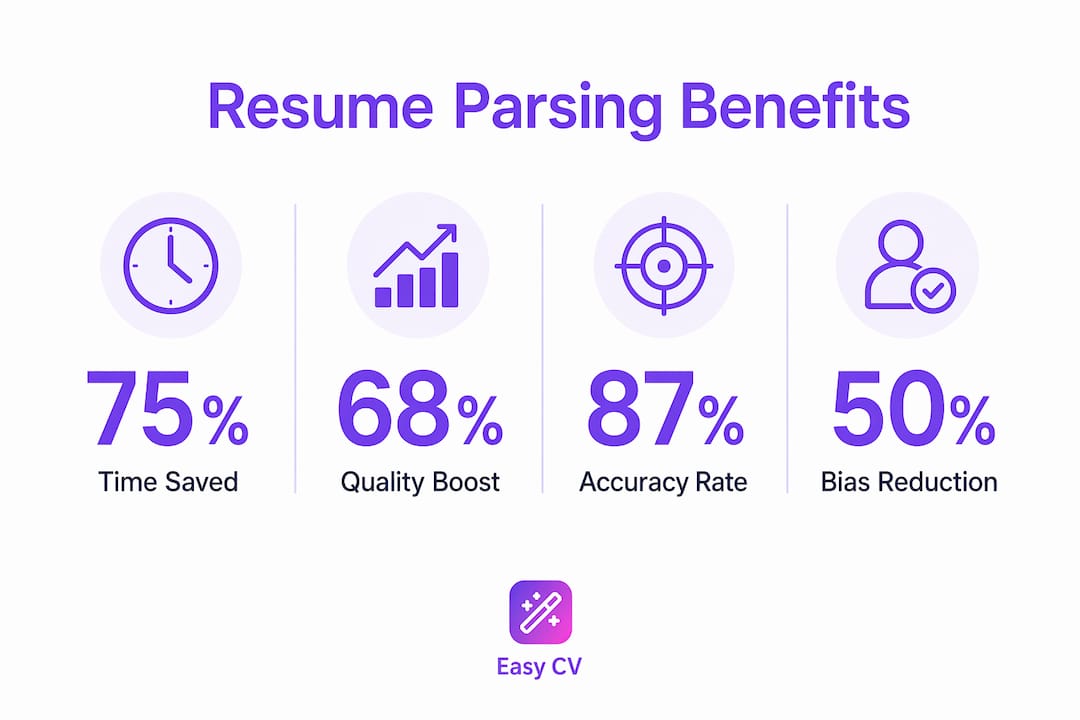
The efficiency gains go further. Automated screening can cut initial screening time by up to 75% compared to manual reviews, which historically took up to 23 hours per hire. That is not a minor improvement. It fundamentally changes how many candidates a recruiter can realistically evaluate.
For job seekers, the benefits are less obvious but equally significant:
- Faster visibility. Your resume reaches a recruiter’s shortlist faster when parsing works correctly.
- Fairer evaluation. Parsing removes subjective reactions to resume design, font choices, or visual presentation.
- Standardized comparison. Your qualifications are measured against the same criteria as every other candidate.
- Keyword matching. Parsers extract your skills and match them directly to job description requirements.
The standardization point deserves attention. 68% of HR professionals believe AI parsing improves candidate quality by focusing evaluation on qualifications rather than subjective resume appearance. That means a well-structured resume from a less-known university can compete on equal footing with a visually polished one from a prestigious school, as long as the content is right.
Parsing also reduces unconscious bias. When a system extracts job titles and skills without seeing a candidate’s name or photo, the initial screening becomes more objective. That is a genuine structural advantage for job seekers who might otherwise face bias in manual screening.
What common challenges and limitations does resume parsing present?
Parsing is powerful, but it is not perfect. Even the most advanced parsers reach roughly 87% field-level accuracy, meaning about 1 in 8 data fields is missed or incorrectly extracted. That error rate sounds small until you realize a missed job title or dropped certification could remove you from a shortlist entirely.
The most common parsing failures come from these sources:
- Scanned or image-based PDFs. If your resume was scanned rather than exported as a native PDF, the parser cannot read it. The file looks like a picture, not text.
- Non-standard section headers. Labels like “Where I’ve Worked” or “Things I Know” confuse classifiers trained on conventional headers like “Work Experience” and “Skills.”
- Complex layouts. Multi-column designs, text boxes, and tables often break the text extraction stage. The parser may read columns out of order or skip content entirely.
- Graphics and icons. Skill bars, profile photos embedded in the document, and decorative icons add visual noise that disrupts parsing.
- Unusual file formats. JPG, PNG, and other image formats are not parseable by standard ATS software. Stick to .docx, text-based PDF, or RTF.
Roughly 23% of early candidate rejections trace directly back to parsing errors in ATS systems. That is a significant share of rejections that have nothing to do with your actual qualifications.
When a parser fails completely, the ATS either flags the resume for manual review or rejects it automatically. Manual review adds days to the process and is not guaranteed. Some systems simply discard unreadable files.
Pro Tip: After building your resume, paste the full text into a plain text editor like Notepad. If the content reads logically from top to bottom, a parser will likely handle it well. If the text is jumbled or out of order, your layout is probably too complex.
How can job seekers optimize their resumes for ATS parsing?
Optimizing your resume for parsing does not mean making it boring. It means making it readable by machines without sacrificing clarity for humans. The two goals are compatible when you follow a few clear rules.
- Use standard section headers. Label your sections “Work Experience,” “Education,” “Skills,” and “Certifications.” These are the labels parsers are trained to recognize. Creative alternatives create classification errors.
- Save as a text-based PDF or .docx. Export your resume directly from a word processor. Never scan a printed copy. Text-based files give parsers clean, extractable text.
- Keep your layout to a single column. Multi-column layouts confuse text extraction. A single-column format reads left to right and top to bottom, exactly how parsers process text.
- Avoid tables, text boxes, and headers/footers. Content inside these elements is often skipped entirely. Put your contact information in the main body of the document, not in a header field.
- Mirror keywords from the job description. Parsers match your resume against the job posting. If the posting says “project management” and your resume says “program oversight,” the match may not register. Use the exact phrasing from the job description where it accurately reflects your experience.
Keyword strategy deserves its own focus. Read the job description carefully and identify the specific skills, tools, and qualifications listed. Then check whether your resume uses the same terminology. An AI resume builder based on job descriptions can automate this matching process, pulling the right keywords and placing them naturally in your content.
Pro Tip: Run your resume through a plain text conversion before submitting. Copy everything into a plain text file and read it straight through. This simulates what a parser sees. Fix any sections that appear out of order or lose their meaning without formatting.
Formatting consistency also matters. Use the same date format throughout, for example “January 2022 – March 2024,” and list your most recent experience first. Parsers are trained on chronological resumes and handle reverse-chronological order best. Functional or hybrid formats often produce more parsing errors because the work history is not where the system expects to find it.
Understanding resume analytics can also help you track which versions of your resume perform better across different applications, giving you data to refine your approach over time.
Key takeaways
Resume parsing is the first filter your application faces, and getting it right requires a clean format, standard headers, and keyword alignment with the job description.
| Point | Details |
|---|---|
| Parsing precedes human review | A parser reads your resume before any recruiter does, making machine readability critical. |
| Five-stage pipeline | Parsing runs through text extraction, tokenization, classification, NER, and structured output. |
| 87% accuracy ceiling | Even top parsers miss about 1 in 8 fields, so clean formatting reduces your risk of errors. |
| File format matters | Use text-based PDFs or .docx files. Scanned images and JPGs cannot be parsed. |
| Keywords drive matching | Mirror the exact language from job descriptions to improve your ATS match score. |
Why most job seekers are fighting a battle they do not know exists
I have reviewed hundreds of resumes over the years, and the most common mistake is not a weak summary or a missing achievement. It is a resume that looks great on screen but falls apart the moment a parser touches it. Candidates spend hours perfecting their bullet points and then submit a two-column PDF with a skills bar graphic on the left side. The parser reads the columns out of order, misses half the work history, and the recruiter never sees a complete profile.
The uncomfortable truth is that parsing technology is still evolving, with multilingual parsing, automatic profile summaries, and better job description matching all improving year over year. But right now, in 2026, the gap between what parsers can handle and what designers produce in resume templates is still wide enough to cost qualified candidates real opportunities.
My honest advice: treat your resume as a data document first and a design document second. The recruiter who eventually reads it will appreciate clear, well-organized content far more than a stylish layout. And the parser that processes it first will reward simplicity every time. If you want to understand how your resume performs before it reaches a recruiter, an AI-driven writing workflow gives you a structured way to build and test parsing-friendly content from the start.
The job seekers who get shortlisted are not always the most qualified. They are often the ones whose resumes the system could actually read.
— Andras
How Easy-cv helps you build a resume that parsers can actually read
Knowing the rules of resume parsing is one thing. Applying them consistently across every application is another challenge entirely.
Easy-cv is built for exactly this problem. Its AI CV builder generates ATS-friendly resumes using clean, single-column templates that pass parsing without errors. The AI writing assistant tailors your content to each job description, matching keywords automatically so your skills align with what the parser is looking for. Every template exports as a text-based PDF, eliminating the scanned-image problem entirely. With 10 million+ job listings added monthly and a built-in job tracker, Easy-cv keeps your entire search organized in one place. You can also explore the full feature set to see how each tool supports your application from first draft to final submission.
FAQ
What is resume parsing in simple terms?
Resume parsing is software that reads your resume and converts it into structured data that an ATS can search and sort. It extracts fields like job titles, skills, and dates automatically.
How does resume parsing work with ATS systems?
The parser processes your resume through a five-stage pipeline and outputs structured data in a format like JSON. The ATS then stores and searches that data to match candidates to job openings.
Is resume parsing effective at finding the right candidates?
Parsing reduces screening time by up to 75% and improves evaluation consistency, but it reaches only about 87% field-level accuracy. Poorly formatted resumes increase the error rate significantly.
What is CV parsing and is it different from resume parsing?
CV parsing and resume parsing refer to the same technology. The term “CV” is more common in Europe and the UK, while “resume” is standard in the United States. The underlying process is identical.
What file format works best for resume parsing?
Text-based PDFs and .docx files are the most reliably parsed formats. Scanned PDFs, JPGs, and PNG files cannot be read by standard parsing software and should never be used for job applications.